Understanding Verification
Verification is a service designed specifically for identifying keywords and phrases in children’s speech; Given an audio file containing children’s speech and one or more target keywords or phrases, the system will return the confidence score of recognition for the word(s) or phrase(s) within the the audio file.
When to Use Verification
SoapBox Verification has been built for those who are developing literacy aids and language learning products, multiple choice games, or highly scripted conversations. These applications have the following things in common and present some of the best applications suited for Verification:
The developer knows in advance the word(s) or phrase(s) they want to score
A score is required for each of these particular words or phrases
The audio file is less than 30 seconds in length
Keyword Spotting: Verification vs. Recognition
A common strategy that has been attempted for keyword spotting in speech has been to use speech recognition methods; however, this strategy has been demonstrated to be less effective than verification for the same use-case.
When using speech recognition for keyword spotting, it is possible and probable that the transcription will not contain all of the words the child has actually said. In this case, it is impossible to calculate confidence scores for every word, prompted or otherwise.
A typical scenario may be as follows: The developers know in advance the word or phrase that the child has been prompted to speak. They send an audio file to a speech recognition system with the intention of searching for this word or phrase in the recogniser output and in-turn, use the associated confidence score as a measure of pronunciation quality.
However, even if the recognition is good, it is heavily influenced by a language model and children frequently under-articulate words or pronounce them in ways that may be recognisable but sub-optimal such that a speech recogniser will often prefer a word that is confusable with the badly pronounced target word.
The result is that when the recogniser fails to return a confidence score for every word of interest, it is then required to build a way of parsing the recogniser output in a meaningful way - an arduous and case/domain specific task.
In contrast, by supplying the keyword or phrase targets with the audio file as with the Verification system, simultaneously allows for a pronunciation score to be returned for every word regardless of how unlikely it was that the word was spoken by the child. The verification system does not require tuning to a particular domain and can work for any short input word or phrase.
Working with Verification: Targets
Verification has been designed as a modularised, API driven technology that can be directly integrated into your project. For more details on how to do this, please see the Technical Docs . The following describes the concept of Targets that are required for working with verification and how these targets are interpreted.
What are Targets
Targets are specific words or phrases that you want to search for or verify exist in an audio sample.
In a lot of use cases, especially involving children, we have an idea of what the child might have or should have said. Verification allows you to check for these specific utterances using Targets. Targets can also be keywords that you might want to search for in a larger phrase or sentence.
Every Verification request requires the presence of at least one target. You may also specify multiple targets which will be assessed concurrently.
Using a Single Target
If an audio file is uploaded with one keyword or phrase, the Soapbox API will return the confidence score for that word or phrase. Depending on the application, this can be interpreted as a likelihood that the given word or phrase was spotted within the audio file, or as a measure of how well the word or phrase was pronounced.
Using Multiple Targets
If an audio file is uploaded with multiple keywords, the Soapbox API will return the confidence scores for the highest scoring keywords. The most usual application of the multiple target mode is “Command & Control” or “Multiple Choice (MCQ)” applications, such as voice-activated action games, and conversational or dialog games.
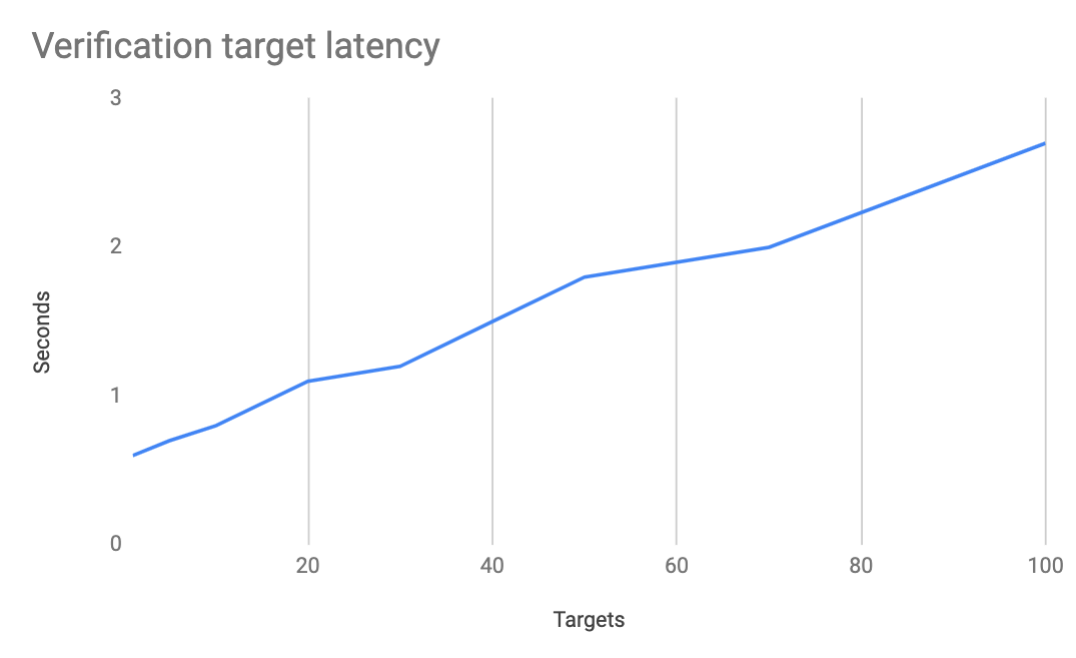
* There is no upper limit on the number of targets that can be specified in a request. The complexity of the request increases with each target specified and in turn this impacts the latency (the length of time it takes to process) of the request. The following table shows approximate request latency to number of targets and is intended only as a guide. The test was performed with an audio file of 4 seconds and which contains a single utterance:
Technical Documentation
Further detail is available in the here.