Audio Quality Feature
Why have we added the Audio Quality Feature?
Poor audio quality can impact on a students score, causing a ‘fail’ result even when the student has responded correctly.
When this happens, the educator has no visibility as to why a student has ‘failed’.
What is the SoapBox Audio Quality Feature?
Poor audio quality can impact on a students score, causing a ‘fail’ result even when the student has responded correctly.
When this happens, the educator has no visibility as to why a student has ‘failed’.
Audio quality, such as the level of background noise or Signal-to-Noise Ratio (SNR), is important in ASR because it directly influences the clarity and quality of the input speech signal, affecting the performance and robustness of the ASR system in various real-world conditions.
We have responded to this problem by adding an SNR value to the JSON output for all of our endpoints. This returns an additional data point to customers that enables them to identify potential problem audio files.
SNR (Signal-to-Noise Ratio) gives a number value for the ratio of background noise to speech.
Signal | clean speech without background noise |
|---|---|
Noise | background noise / background speech |
All audio files will have background noise, using an SNR value helps to identify whether the level is potentially problematic.
Where to find the Audio Quality Feature
The SoapBox audio_quality node is a data object at root level in the SoapBox engine JSON output. It groups all the metrics that represent different audio quality dimensions.
The higher the estimated SNR value is, the lower the noise energy level is compared to the speech part, and hence the more audible the speech content is.
A low-energy background noise allows the speech decoder to transcribe an input audio file more accurately.
audio_quality: {
…
"SNR": XX,
…
}
The loud background noise is one of the most challenging factors in real-world recordings that affect the accuracy of ASR transcriptions. In most common EdTech use cases (close on-device microphone recordings), fewer chances are that the audio quality degradation is caused by reverberation or spectral coloration.
Thus, the SoapBox audio_quality object contains a datapoint (SNR) that returns the audio quality of a file from the noisiness angle.
The SNR value consists of an estimation of the signal to noise energy ratio.
Since the engine does not have access to clean speech and the noise signals separately, a SNR estimation is provided. SNR estimation involves deriving the SNR value without directly measuring the signal and noise levels through algorithms or statistical methods.
The call to the SoapBox API returns one SNR value (in dB) per file.
If the SNR is higher than the selected threshold value, the audio is regarded as high quality and the ASR output is likely to be reliable. If the SNR is lower than the threshold, then the output ASR transcript from the engine might not be reliable.
Customers can tune the most appropriate threshold to determine the minimum acceptable SNR.
The threshold might vary according to the use cases: e.g., the type of exercise, the speech rate, the distance to the microphone, etc.
How to interpret the SNR values
Higher SNR generally corresponds to better speech quality. When the SNR is low, the speech signal may be degraded and harder to understand, leading to errors in transcription.
SNR value is a number that ranges between -20 and 100. If the SNR computation fails, e.g. the audio file being too short (< 0.5 s), 500 is returned in the SNR value.
An overview of the value ranges is reported in the Table below.
SNR Range | Meaning | Action |
-20 to -1 | extremely noisy file | Audio should be discarded |
0 to 9 | very noisy file | Decoder results might have reduced accuracy |
10 to 19 | noisy file | Decoder might be able to produce reliable results |
20 to 39 | clean file | Decoder’s results are reliable |
40 to 99 | extremely clean file | Decoder’s results are reliable |
100 | default clean value | File is empty. Or it has a great proportion of silence w.r.t speech. |
500 | default error value | SNR computation failed |
What is Audio Quality?
The audio quality of a speech signal is a set of subjective measures based on human hearing and perception. It could be separated into several dimensions such as spectral coloration, discontinuity, noisiness, audio samples clipping, loudness, degree of articulation, etc.
Poor audio quality often affects the intelligibility of a speech signal for both humans and machines, and, below a certain level quality threshold level, speech content cannot be parsed correctly.
Why is Audio Quality important in Speech Recognition?
The audio quality assessment of a speech signal can effectively predict the likelihood of an audio signal to be decoded accurately by Automatic Speech Recognition (ASR) systems. The higher the audio quality of the input audio, the more reliable and accurate is the Engine ASR output, and vice versa.
Audio quality assessment consists of a set of perceptual measures/estimates to predict how clearly the speech contents in the audio would be perceived by humans.
One of the key and most common dimensions to describe audio quality is the level of noisiness of a speech signal. This is commonly reported as the Signal to Noise ratio or SNR . SNR is a measure used in various fields, including telecommunications, audio engineering, and electronics, to quantify the ratio of a desired signal to the background noise.
Generally, in speech signals, a higher SNR indicates a better audio quality because the speech parts are louder relative to the noise.
It is expressed in decibels (dB). A positive SNR indicates that the signal is stronger than the noise. A negative SNR suggests that the noise is stronger than the signal. High SNR, normally above 20dB, is desirable.
How is the Audio Quality represented in the output JSON?
The SNR estimation computed by the SoapBox engine is surfaced in the JSON output with the SNR attribute in the audio_quality node.
{
"audio_duration": 0.886,
"audio_quality": {
"SNR": 34
},
"language_code": "en-GB",
"result_id": "RESULT_ID",
"time": "TIME",
"user_id": "USER_ID",
"engine_latency": 55.95,
"server_id": "SERVER_ID",
"results": [
{
"category": "chicken",
"hypothesis_score": 96,
"word_breakdown": [
{
"quality_score": 96,
"target_transcription": "ch ih k ah n",
"word": "chicken",
"token_type": "word",
"phone_breakdown": [
. . .
],
"end": 0.84,
"start": 0.03,
"pitch": {
"values": []
},
"duration": 0.81
}
],
"end": 0.84,
"start": 0.03,
"duration": 0.87,
"hypothesis_duration": 0.81
}
]
}
HOW AUDIO QUALITY FEATURE OUTPUT CAN BE COMBINED TO OTHER DECODER DATA POINTS?
The audio quality feature helps to detect poor audio quality files and to discard them if needed. These values can also be combined with other data points in the JSON engine output to boost the confidence of the detection.
An example of how to aggregate the SoapBox audio quality data point (i.e. the SNR estimation) with other data points from the JSON output is reported below.
Two speech data points derived from the decoder output that are proven to be effective are:
The passage-level
confidencevalueThe ratio between the length of the speech part in the audio (the sum of the word-level
durationvalues) and the total audio duration (theoverall_durationvalue).
The combination of the three values can be combined with linear equations to produce an aggregated score that detects poor audio quality files with a confidence as high as a human listeners' assessment.
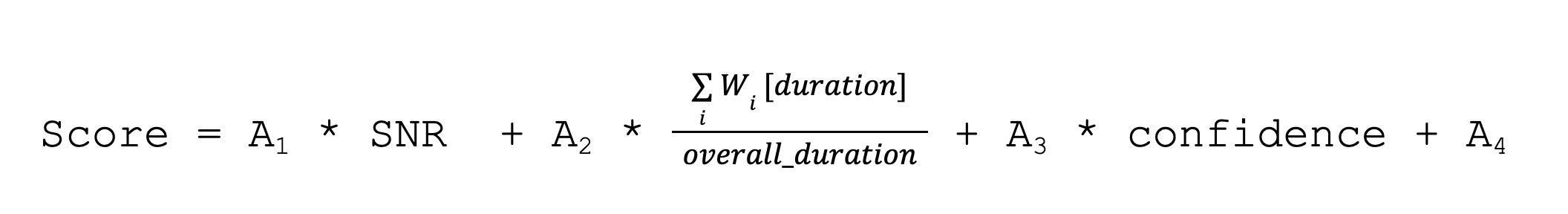
The values A1 , A2 , A3 and A4 can be optimized on the desired use cases with optimization techniques (e.g. linear regression).