Customizing Text Using Markup
What is Markup?
Markup is simply a way to annotate text in a document. It is used to add instructions for specific content, such as a letter, word, paragraph, or even the entire page. An advantage of markup languages is that the original text and the markup instructions are intermixed in the same document. This can prevent errors and makes the experience easier for the user.
Markup is used widely across the IT industry and each form follows a similar structure where target content is placed between a pair of corresponding tags. Optional information can be added using specific attributes, but these are not always required.
Markup Element / Instruction
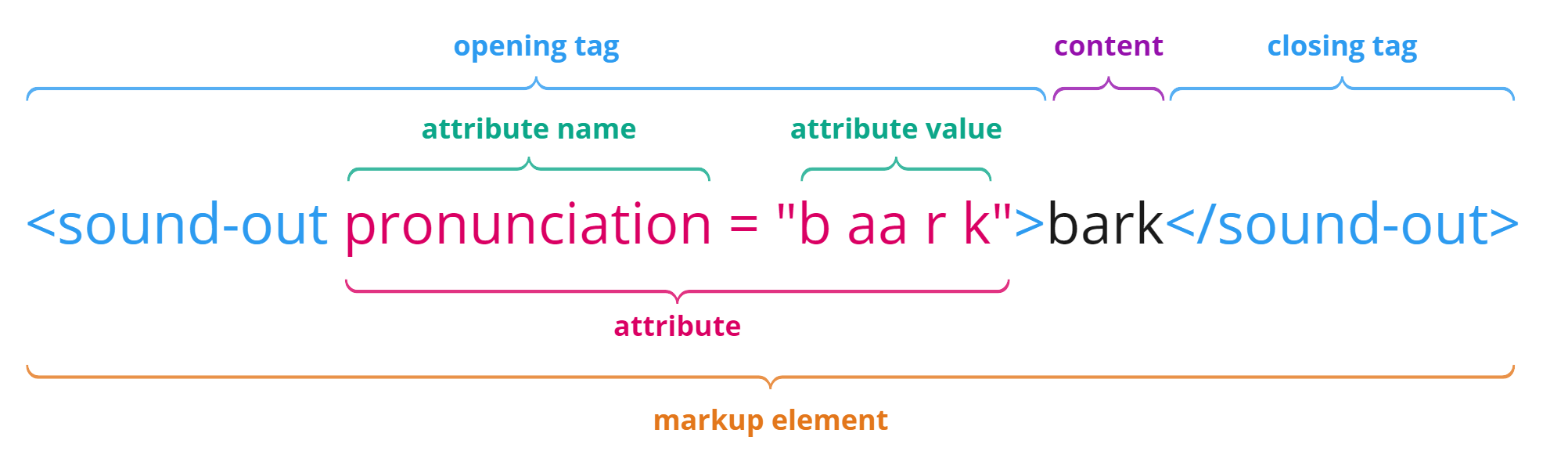
A markup instruction is also known as an element. Here is a diagram which shows the basic components of a markup element.
What is a Tag?
A markup tag is a keyword that instructs the engine to treat some content (letter, word, number etc) in a special way. Tags are enclosed inside angled-brackets, like <this>. They are pre-defined and have a specific meaning to the engine that parses them. Each markup element consists of an opening tag and a corresponding closing tag with some content in between. This tells the engine where the markup element begins and ends.
Every opening tag must have a corresponding closing tag!
For example, suppose we have an engine that parses a document and then displays the text on a web page. If we want to tell the engine that a certain word should be displayed in bold then our original text might look like the following:
I will follow up <bold>asap</bold>
This would then be displayed as:
I will follow up asap
In the example above we told the engine to display the content “asap” in bold by placing it between the relevant opening and closing tags. Note that we included a forward-slash, “/”, symbol at the start of the closing tag. This tells the engine that it is the end of our instruction. If we left out this symbol the engine would instead detect two opening tags and no closing tag. This would cause an error!
Summary:
A tag is a keyword that instructs the engine to treat content in a special way
Tags are enclosed in <…> brackets
Every opening tag must have a corresponding closing tag
Closing tags are detected when a forward-slash symbol is placed before the tag name, </…>
What is an Attribute?
Attributes are usually optional and are part of the opening tag, but never the closing tag! They are used to give the engine more information about the markup element. We assign the attribute a value using the = sign. This value should be inside double quotes, like this: name = "value". An opening tag can have more than one attribute, and the order doesn't matter.
For example, we want to tell our engine that a certain piece of text should be displayed as a hyperlink. Our original text would look like the following:
Please visit my website <link url = "mywebsite.me">here</link>
Which would then get displayed as
Please visit my website here
The word “here” becomes a hyperlink when the text is displayed, and when the user clicks on it they would be taken to the address provided by the “url” attribute.
Summary:
Attributes are usually optional
They are part of the opening tag, and never the closing tag
They follow the pattern:
name = "value"
Introduction to Text Normalization
When using speech technology, a process called “text normalization” must be used on all input words, sentences, and paragraphs. When text is provided to SBL for the building of a CLM, or when a CURL request is sent to the Fluency Web Service, text normalization happens under the hood to ensure the text is compatible with SBL systems. Some portions of the text are pre-normalized by the customer (as per CLM guidelines), and other portions of the text are normalized automatically by SBL.
Typical examples of text normalization include:
stripping punctuation
lowercasing all letters
changing digits to words
Example:
“I have 2 you can borrow,” she said → i have two you can borrow she said
Text normalization helps to ensure the best possible performance of our speech technology.
Default vs Custom Normalization
Standard normalization such as lowercasing and stripping punctuation are straight-forward processes. However, some aspects of text have numerous ways they can be normalized. A key example is digits in text.
If we use “1991” as an example, we see that this can be said in the following ways:
nineteen ninety one
one thousand nine hundred ninety one
one thousand nine hundred and ninety one
one nine nine one
Because of this ambiguity, we give customers the option to customize the way certain opaque texts are normalized. However, we maintain a default setting for all text in case this customization is not utilized or needed.
Using Markup for Custom Normalization
We have defined some markup tags in our engine which can be useful for specifying how some content should be normalized. This can be used both in the CLM text sent to SBL and the CURL request sent to the Fluency Web Service.
Here is a quick example which shows the difference between default and custom normalization:
In <year>1776</year>, the declaration of independence was signed.
If this markup is used, the sentence will be normalized to:
in seventeen seventy six the declaration of independence was signed
If this mark is not used, the sentence will be normalized to:
in one thousand seven hundred seventy six the declaration of independence was signed
Use Cases & Examples
We currently support mark-up for the following use cases:
Years and Decades
Dates
Email Addresses
Letters
Sounding Out
Custom Word
Years and Decades

Years and decades can both be normalized using the year tag. It will ensure that years and decades in the text are not interpreted as cardinal numbers. The content must consist of digits only, but decades can have a trailing 's' at the end. There are no available attributes for this tag.
Correct Usage:
In
<year>1913</year>, I sold 1913 apples.in nineteen thirteen i sold one thousand nine hundred thirteen apples
In
<year>1776</year>, the declaration of independence was signed.in seventeen seventy six the declaration of independence was signed
Grandma’s birthday is on August 2nd,
<year>1945</year>grandmas birthday is on august second nineteen forty five
The Second World War was from
<year>1939</year>to<year>1945</year>the second world war was from nineteen thirty nine to nineteen forty five
100 dollars in the
<year>1800s</year>is equivalent to 1,904 dollars today.one hundred dollars in the eighteen hundreds is equivalent to one thousand nine hundred four dollars today
The women’s suffrage movement in Canada began in the
<year>1870s</year>the womens suffrage movement in canada began in the eighteen seventies
If I could go to any decade, I’d go to the
<year>80s</year>, or maybe the<year>50s</year>if i could go to any decade id go to the eighties or maybe the fifties
Incorrect Usage:
<year>19 13</year>Cannot have spaces in the middle of year content
<year>nineteen thirteen</year>Content must consist of digits with an optional 's' at the end
<year>1913<year>No / symbol in closing tag!
Dates

Dates are normalized using the <date> tag. Currently we only support dates in US format (month/day/year), where each component is a numerical value. For instance, January can be written as 1, or 01 etc. The year value is optional. There are no available attributes for this tag.
Correct Usage:
It was
<date>10/25/2021</date>it was october twenty fifth twenty twenty one
John bought a new car on
<date>1/9/1999</date>john bought a new car on january ninth nineteen ninety nine
St. Patricks Day is always on
<date>03/17</date>st patricks day is always on march seventeenth
Incorrect Usage:
<date>13/04/21</date>Month values must be between 1 and 12
<date>january/10</date>Components must be numerical values
<date>01-01-2022</date>Components must be separated by a “/” symbol
Email Addresses

Email addresses are normalized using the <email> tag. The content can consist of letters, numbers, and most special characters. To keep things simple most symbols are ignored and numbers will be normalized as singular digits. There are no available attributes for this tag.
Correct Usage:
My email address is
<email>john_doe17@hotmail.com</email>.my email address is john doe one seven at hotmail dot com
Please contact me at
<email>jane42@test-mail.co.uk</email>please contact me at jane four two at test mail dot co dot uk
Incorrect Usage:
<email>jane doe@hotmail.com</email>Spaces are not allowed in email addresses!
<email>john.doe.hotmail.com</email>No @ symbol detected
<email>john@doe@hotmail.com</email>More than one @ symbol detected
Letters

Letters are normalized using the <letter> tag. They have an optional pronunciation attribute which allows the user to specify the desired phoneme breakdown. Phonemes must be separated by a space. Only a single letter is allowed in the content.
Correct Usage:
<letter>X</letter>x
<letter pronunciation = "ey">a</letter>a
<letter pronunciation = "hh ey ch">H</letter>h
Incorrect Usage:
<letter>ay</letter>Content must consist of a single letter only
<letter pronunciation = "eych">h</letter>Each phoneme must be 1 or 2 characters long
<letter pron = "k s">x</letter>Invalid attribute name
Sounding Out

Sounding out a word can be achieved using the sound-out tag. Only singular valid words are supported and must not contain spaces or hyphens. There is an optional pronunciation attribute for specifying the phoneme breakdown. The phonemes must be separated by a space. When the sound-out tag is used for isolated phonemes/phonics (e.g., hh or o), the pronunciation attribute is always required, because these entries are not words in the dictionary.
Correct Usage:
<sound-out>Tree</sound-out>t r iy
<sound-out pronunciation = "b ao r k">bark</sound-out>b ao r k
<sound-out pronunciation = "k ae t">dog</sound-out>k ae t
<sound-out pronunciation = "hh">hh</sound-out>hh
<sound-out pronunciation = "ao">o</sound-out>ao
<sound-out pronunciation = "v uw s" > voos </sound-out>v uw s
Incorrect Usage:
<sound-out>hello world</sound-out>Content contains more than one word
<sound-out>round-trip</sound-out>Content contains a hyphenated word
<sound-out pronunciation = "ks"> x </sound-out>no space in the phoneme sequence
<sound-out pronunciation = "a"> a </sound-out>the symbol “a” is not a valid phoneme
Custom Words

The custom-word tag is used to add custom or made up words. Note that the pronunciation attribute is compulsory! This is to allow the engine know what the phoneme breakdown is, even if it's a valid word that exists in the language.
Correct Usage:
<custom-word pronunciation = "v uw s">voos</custom-word>voos
<custom-word pronunciation = "m ae s">mas</custom-word>mas
Incorrect Usage:
<custom-word>voos</custom-word>Requires pronunciation attribute
<custom-word pronunciation = "m ae s k aa t">mas cot</custom-word>Content contains more than one word
What is markup?
Markup is simply a way to annotate text in a document. It is used to add instructions for specific content, such as a letter, word, paragraph, or even the entire page. An advantage of markup languages is that the original text and the markup instructions are intermixed in the same document. This can prevent errors and makes the experience easier for the user.
Markup is used widely across the IT industry, and each form follows a similar structure where target content is placed between a pair of corresponding tags. Optional information can be added using specific attributes, but these are not always required.
Markup element / instruction
A markup instruction is also known as an element. Here is a diagram showing the basic components of a markup element.
What is a tag?
A markup tag is a keyword that instructs the engine to treat some content (letter, word, number, etc.) in a special way. Tags are enclosed inside angled-brackets, like <this>. They are pre-defined and have a specific meaning to the engine that parses them. Each markup element consists of an opening tag and a corresponding closing tag with some content in between. This tells the engine where the markup element begins and ends.
Every opening tag must have a corresponding closing tag!
For example, suppose we have an engine that parses a document and then displays the text on a web page. If we want to tell the engine that a certain word should be displayed in bold, then our original text might look like the following:
I will follow up <bold>asap</bold>
This would then be displayed as:
I will follow up asap
In the example above, we told the engine to display the content “asap” in bold by placing it between the relevant opening and closing tags. Note that we included a forward-slash, “/”, symbol at the start of the closing tag. This tells the engine that it is the end of our instruction. If we left out this symbol, the engine would instead detect two opening tags and no closing tag. This would cause an error!
Summary
A tag is a keyword that instructs the engine to treat content in a special way.
Tags are enclosed in <…> brackets.
Every opening tag must have a corresponding closing tag.
Closing tags are detected when a forward-slash symbol is placed before the tag name, </…>.
What is an attribute?
Attributes are usually optional and are part of the opening tag, but never the closing tag! They are used to give the engine more information about the markup element. We assign the attribute a value using the = sign. This value should be inside double quotes, like this: name = "value". An opening tag can have more than one attribute, and the order doesn't matter.
For example, we want to tell our engine that a certain piece of text should be displayed as a hyperlink. Our original text would look like this:
Please visit my website <link url = "mywebsite.me">here</link>
Which would then get displayed as
Please visit my website here
The word “here” becomes a hyperlink when the text is displayed, and when the user clicks on it they would be taken to the address provided by the “url” attribute.
Summary:
Attributes are usually optional.
They are part of the opening tag, and never the closing tag.
They follow the pattern:
name = "value".
Introduction to text normalization
When using speech technology, a process called “text normalization” must be used on all input words, sentences, and paragraphs. When text is provided to SoapBox Labs for the building of a custom language model (CLM), or when a CURL request is sent to the Fluency Web Service, text normalization happens under the hood to ensure the text is compatible with SoapBox systems. Some portions of the text are pre-normalized by the customer (as per CLM guidelines), and other portions of the text are normalized automatically by SoapBox.
Typical examples of text normalization include:
stripping punctuation
lowercasing all letters
changing digits to words
Example:
“I have 2 you can borrow,” she said. → i have two you can borrow she said
Text normalization helps to ensure the best possible performance of our speech technology.
Default normalization vs using markup for normalization
Standard normalization, such as lowercasing and stripping punctuation, are straight-forward processes. However, some aspects of text have numerous ways they can be normalized. A key example is digits in text.
If we use “1991” as an example, we see that this can be said in the following ways:
nineteen ninety one
one thousand nine hundred ninety one
one thousand nine hundred and ninety one
one nine nine one
Because of this ambiguity, we give customers the option to customize the way potentially messy pieces of text are normalized. However, we maintain a default setting for all text in case this customization is not utilized or needed.
Here are a few examples of the default normalization for years and dates:
Text | Default normalization |
|---|---|
1991 | one thousand nine hundred ninety one |
2022 | two thousand twenty two |
10/25/2021 | ten million two hundred fifty two thousand twenty one |
And the same examples when using markup
Text | Using markup tag | Markup normalization |
|---|---|---|
1991 | <year> | nineteen ninety one |
2022 | <year> | twenty twenty two |
10/25/2021 | <date> | october twenty fifth twenty twenty one |
Using markup for normalization
We have defined some markup tags in our voice engine, which can be useful for specifying how some content should be normalized. This can be used both in the CLM text sent to SoapBox and the CURL request sent to the Fluency Web Service.
Here is a quick example that shows the difference between default and custom normalization:
In <year>1776</year>, the declaration of independence was signed.
If this markup is used, the sentence will be normalized to:
in seventeen seventy six the declaration of independence was signed
If this mark is not used, the sentence will be normalized to:
in one thousand seven hundred seventy six the declaration of independence was signed
Use cases and examples
We currently support markup for the following use cases:
Years and decades
Dates
Email addresses
Letters
Sounding out
Custom words
Years and decades
Years and decades can both be normalized using the year tag. It will ensure that years and decades in the text are not interpreted as cardinal numbers. The content must consist of digits only, but decades can have a trailing 's' at the end. There are no available attributes for this tag.
Correct Usage:
In
<year>1913</year>, I sold 1913 apples.in nineteen thirteen i sold one thousand nine hundred thirteen apples
In
<year>1776</year>, the declaration of independence was signed.in seventeen seventy six the declaration of independence was signed
Grandma’s birthday is on August 2nd,
<year>1945</year>.grandmas birthday is on august second nineteen forty five
The Second World War was from
<year>1939</year>to<year>1945</year>.the second world war was from nineteen thirty nine to nineteen forty five
100 dollars in the
<year>1800s</year>is equivalent to 1,904 dollars today.one hundred dollars in the eighteen hundreds is equivalent to one thousand nine hundred four dollars today
The women’s suffrage movement in Canada began in the
<year>1870s</year>.the womens suffrage movement in canada began in the eighteen seventies
If I could go to any decade, I’d go to the
<year>80s</year>, or maybe the<year>50s</year>if i could go to any decade id go to the eighties or maybe the fifties
Incorrect Usage:
<year>19 13</year>Cannot have spaces in the middle of year content
<year>nineteen thirteen</year>Content must consist of digits with an optional 's' at the end
<year>1913<year>No / symbol in closing tag!
Dates
Dates are normalized using the <date> tag. Currently, we only support dates in US format (month/day/year), where each component is a numerical value. For instance, January can be written as 1, or 01 etc. The year value is optional. There are no available attributes for this tag.
Correct Usage:
It was
<date>10/25/2021</date>.it was october twenty fifth twenty twenty one
John bought a new car on
<date>1/9/1999</date>.john bought a new car on january ninth nineteen ninety nine
St. Patricks Day is always on
<date>03/17</date>.st patricks day is always on march seventeenth
Incorrect Usage:
<date>13/04/21</date>Month values must be between 1 and 12
<date>january/10</date>Components must be numerical values
<date>01-01-2022</date>Components must be separated by a “/” symbol
Email addresses
Email addresses are normalized using the <email> tag. The content can consist of letters, numbers, and most special characters. To keep things simple, most symbols are ignored and numbers will be normalized as singular digits. There are no available attributes for this tag.
Here’s a summary of how symbols are normalized:
Symbol | Markup normalization |
|---|---|
0 - 9 | zero - nine |
@ | at |
. | dot |
_ - ! £ $ % ^ & * ( ) + = { } | [ ignored ] |
Correct Usage:
My email address is
<email>john_doe17@hotmail.com</email>.my email address is john doe one seven at hotmail dot com
Please contact me at
<email>jane42@test-mail.co.uk</email>.please contact me at jane four two at test mail dot co dot uk
Incorrect Usage:
<email>jane doe@hotmail.com</email>Spaces are not allowed in email addresses!
<email>john.doe.hotmail.com</email>No @ symbol detected
<email>john@doe@hotmail.com</email>More than one @ symbol detected
Letters
Letters are normalized using the <letter> tag. They have an optional pronunciation attribute, which allows the user to specify the desired phoneme breakdown. Phonemes must be separated by a space. Only a single letter is allowed in the content.
Correct Usage:
<letter>X</letter>x
<letter pronunciation = "ey">a</letter>a
<letter pronunciation = "hh ey ch">H</letter>h
Incorrect Usage:
<letter>ay</letter>Content must consist of a single letter only
<letter pronunciation = "eych">h</letter>Each phoneme must be 1 or 2 characters long, and phonemes must be separated by spaces
<letter pron = "k s">x</letter>Invalid attribute name
Sounding out
Sounding out a word can be achieved by using the sound-out tag. Only singular valid words are supported and must not contain spaces or hyphens. There is an optional pronunciation attribute for specifying the phoneme breakdown. The phonemes must be separated by a space. When the sound-out tag is used for isolated phonemes/phonics (e.g., hh or o), the pronunciation attribute is always required, because these entries are not words in the dictionary.
Correct Usage:
<sound-out>Tree</sound-out>t r iy
<sound-out pronunciation = "b aa r k">bark</sound-out>b aa r k
<sound-out pronunciation = "hh">hh</sound-out>hh
<sound-out pronunciation = "ao">o</sound-out>ao
<sound-out pronunciation = "v uw s" >voos</sound-out>v uw s
Incorrect Usage:
<sound-out>hello world</sound-out>Content contains more than one word
<sound-out>round-trip</sound-out>Content contains a hyphenated word
<sound-out pronunciation = "ks"> x </sound-out>no space in the phoneme sequence
<sound-out pronunciation = "a"> a </sound-out>the symbol “a” is not a valid phoneme
Custom words
The custom-word tag is used to add custom or made-up words. Note that the pronunciation attribute is compulsory! This is so the engine knows what the phoneme breakdown is, even if it's a valid word that exists in the language.
Correct Usage:
<custom-word pronunciation = "v uw s">voos</custom-word>voos
<custom-word pronunciation = "m ae s">mas</custom-word>mas
Incorrect Usage:
<custom-word>voos</custom-word>Requires pronunciation attribute
<custom-word pronunciation = "m ae s k aa t">mas cot</custom-word>Content contains more than one word